Hola y bienvenidos a este repaso de probabilidad y estadística. En esta sección vamos a repasar algunos conceptos básicos de probabilidad y estadística que nos van a ser de vital importancia para lo que sigue. No vamos a entrar en detalle1, ni vamos a hacer demostraciones, sino que vamos a tratar de entender los conceptos de forma intuitiva y práctica.
1 Repetimos la recomendación. Si quieren profundizar en alguno de los temas pueden leer el capítulo 1 de (Wasserman 2004) o el repaso de probabilidad de (Cunningham 2021) (disponible online).
Wasserman, Larry. 2004. All of statistics: a concise course in statistical inference. Springer Science & Business Media.
Cunningham, Scott. 2021. Causal inference: The mixtape. Yale university press.
2.1 Eventos aleatorios
Un evento aleatorio es un resultado posible de un experimento aleatorio. Por ejemplo, si tiramos una moneda al aire, los eventos aleatorios posibles son “cara” y “ceca”. Si tiramos dos monedas, los eventos aleatorios posibles son “cara-cara”, “cara-ceca”, “ceca-cara” y “ceca-ceca”. En general, el conjunto de todos los eventos aleatorios posibles se llama espacio de eventos y se denota con la letra \(\Omega\).
2.2 Variables aleatorias
Wasserman(Wasserman 2004) nos dice que una variable aleatoria es un mapeo entre el espacio de eventos y los números reales (\(X:\Omega \rightarrow \mathbb{R}\)). Momento cerebrito ¿Esto que quiere decir? En términos prácticos, lo que implica esta definición es que una variable aleatoria nos da un número para cada evento del posible espacio de eventos aleatorios.
2 Una moneda justa es aquella que tiene la misma probabilidad de dar cara o ceca, es decir, \(P(H) = P(T) = 0.5\).
3 Cara será H, del inglés Head y ceca será T, del inglés Tail.
Vamos con un ejemplo que nos aclare un poco las cosas. Supongan que tiramos una moneda justa2 dos veces y tenemos la variable aleatoria \(X\) que cuenta la cantidad de caras (H)3. Los posibles eventos \(\omega\) del espacio de eventos \(\Omega\) son \(\Omega = \{ TT, TH, HT, HH \}\), es decir, que salga ceca y ceca, ceca y cara, cara y ceca, y cara y cara. Uno podría pensar que la variable aleatoria podría tomar un \(1\) para cara y un \(0\) para ceca, pero recordemos la definición de la variable \(X\). Lo que nos interesa es la cantidad de caras y es por eso que, en este caso, la variable aleatoria \(X\) va a tomar los valores \(X = \{ 0, 1, 1, 2\}\), correspondientes a cada evento aleatorio \(\omega \in \Omega\). Esto, en resumidas cuentas, es lo que hace una variable aleatoria, convertir un evento aleatorio (por ejemplo, \(HH\)) en un valor numérico (en este caso \(2\)).
En el ejemplo anterior \(X\) es lo que se denomina una variable aleatoria discreta, es decir, que sólo puede tomar algunos valores posibles (en este caso \(X = \{ 0, 1, 1, 2\}\)). Pero es importante recordar que también existen variables aleatorias continuas como por ejemplo la altura de una nueva persona que nace o la temperatura de Buenos Aires en un día de enero 🥵.
Una pregunta que nos podemos hacer es: ¿para que nos interesa definir una variable aleatoria si lo que queremos estudiar son los eventos aleatorios? Bueno, porque traducir esos eventos (que pueden ser dos tiradas de monedas o algo mucho más complejo, como tener o no tener una enfermedad) en un número tiene grandes ventajas al momento de modelizar la distribución de probabilidades.
2.3 Probabilidad
El concepto de probabilidad es algo complejo, pero, como esto no es un curso de probabilidad, vamos a confiar en que ustedes ya lo tienen claro. Si tienen coraje pueden ir a leer el capítulo 1 de (Wasserman 2004) y, si quieren algo más terrenal, pueden ir a ver el repaso de probabilidad de (Cunningham 2021) (disponible online). Pero, de forma general, podemos decir que la probabilidad es una medida numérica de la incertidumbre -o la certeza- de que un evento aleatorio ocurra4.
4 Existen dos grandes interpretaciones de la probabilidad: la frecuentista y la bayesiana. La primera define a la probabilidad como la frecuencia relativa de un evento en una serie de experimentos repetidos, mientras que la segunda la define como una medida subjetiva de la creencia o confianza en que un evento ocurra. Si quieren bucear en las profundas aguas de este debate pueden empezar por acá.
5 El enfoque frecuentista de la estadística justamente se basa en controlar los errores dada una repetición infinita de mi experimento.
Como dijimos que tenemos una moneda justa, es razonable pensar que todos los eventos aleatorios en este espacio de eventos \(\Omega = {TT, TH, HT, HH}\) son equiprobables, es decir, que cada uno de ellos tiene la misma probabilidad de ocurrir, ¿no? Entonces, la probabilidad de ocurrencia de cada evento será de \(1/4\)5. ¿Pero podemos decir lo mismo de los posibles valores de X? ¿Tiene la misma probabilidad de valer \(0\) que de valer \(1\)?
Como confío que son gente inteligente,y un poco ansiosa, ya deben haber chusmeado esta tabla y se habrán dado cuenta que la respuesta es no.
\(\omega\)
\(X(\omega)\)
\(P({\omega})\)
TT
0
1/4
TH
1
1/4
HT
1
1/4
HH
2
1/4
Lo que vemos es que hay dos eventos aleatorios (TH y HT) que se “mapean” al mismo valor de X (en este caso 1) y esto hace que la probabilidad de que X tome el valor de 1 no sea de \(1/4\) sino de \(1/2\).
Este bello y simplísimo ejemplo tiene el único objetivo de pensar un poco para qué sirve una variable aleatoria y cómo es diferente de un evento aleatorio. No vamos a entrar en más detalle.
Cuando las variables aleatorias son continuas la cosa se complica un poco más ya que \(P(X=c)\) (por ejemplo, la probabilidad de que una variable tome un valor dado) es cero. Esto lo vamos a repensar un poco en la siguiente sección, cuando definamos lo que nos importa para este libro: las funciones de densidad y de distribución.
2.4 Probabilidad condicional
La probabilidad condicional es la probabilidad de que ocurra un evento \(A\) dado que ocurrió un evento \(B\) y se escribe como \(P(A|B)\). Esta puede calcularse como:
\[
P(A|B) = \frac{P(A \cap B)}{P(B)}
\tag{2.1}\]
donde \(P(A \cap B)\) es la probabilidad de que \(A\) y \(B\) ocurran juntos. Esta fórmula se puede entender fácilmente a partir de la definición de probabilidad como frecuencia relativa. Si tenemos una serie de experimentos repetidos, la probabilidad de que ocurra \(A\) dado que ocurrió \(B\) es simplemente la proporción de veces que ambos eventos ocurrieron juntos (\(P(AB)\)) sobre la proporción de veces que ocurrió B(\(P(B)\)).
Pensemos en el ejemplo de tirar dos monedas justas. Supongamos que queremos saber la probabilidad de que salga exactamente una cara (\(A\)) dado que salió al menos una cara (\(B\)). En este caso, \(P(A \cap B)\) es la probabilidad de que salga exactamente una cara y al menos una cara, lo cual es simplemente la probabilidad de que salga exactamente una cara (\(P(X=1)\)), es decir, \(P(A \cap B) = P(HT) + P(TH) = 1/2\). Por otro lado, \(P(B)\) es la probabilidad de que salga al menos una cara (\(P(X=1)+(P(X=2)\)), lo cual es igual a \(P(B) = P(HT) + P(TH) + P(HH) = 3/4\). Entonces, al reemplazar en la fórmula tenemos que:
Por ahora quedémonos con esta definición simple que será de vital importancia para lo que sigue.
2.5 Probabilidad total
Imaginemos que queremos calcular la probabilidad de un evento B a partir de su relación condicional con A. Para esto, debemos considerar la probabilidad de que ocurra B tanto si A ocurre como si no. Al ponderar cada uno de estos escenarios por la probabilidad de que ocurran (o no), obtenemos lo que se denomina probabilidad total, la cual se expresa de la siguiente forma6:
6 Recordemos que \(\neg\) es el símbolo lógico de la negación.
\[
P(B) = P(B|A) \times P(A) + P(B|\neg A) \times P(\neg A)
\tag{2.3}\]
Pensemos un ejemplo. Imaginemos que una persona tiene que completar un trabajo de jardinería (evento \(B\)) en un día. La probabilidad de que termine este trabajo si llueve (evento \(A\)) es \(0.35\) y la probabilidad de que lo termine si no llueve es de \(0.95\). Si la probabilidad de que llueva es \(P(A)= 0.4\), ¿cuál es la probabilidad (\(P(B)\)) de que el trabajo se complete en un día? Echemos mano a la fórmula de probabilidad total:
Entonces, la probabilidad de completar el trabajo en un día es \(P(B)=0.71\).
Por último, cuando tenemos muchas condiciones, podemos definir de forma general a la probabilidad total como:
\[
P(B) = \sum_n P(B|A_n) P(A_n)
\tag{2.5}\]
🎩¡Matemagia!🎩
Ya que estamos cancheros, supongamos que tenemos el evento \(A_1\) y queremos calcular su probabilidad condicional dado que ocurrió el evento \(B\). Recordemos la definición de probabilidad condicional:
Y como las intersecciones son iguales (\(P(A_1 \cap B) = P(B \cap A_1)\), podemos despejar de la Ecuación 2.7 a \(P(A_1 B) = P(B|A_1) P(A_1)\) y reemplazarlo en la fórmula de probabilidad condicional:
Esto que acabamos de deducir es nada más ni nada menos que la fórmula de Bayes, una de las fórmulas más importantes de la probabilidad y la estadística. La fórmula de Bayes nos permite invertir la condicionalidad de una probabilidad, es decir, calcular \(P(A/B)\) a partir de \(P(B/A)\).
2.6 Teorema de Bayes
Ahora que ya llegamos a la fórmula de Bayes -a partir de las definiciones de probabilidad total- podemos tomar prestado un ejemplo de (Herzog, Francis, y Clarke 2019): Tenemos un test para identificar si somos portadores de un virus (llamémoslo IKV). Este test tiene una sensibilidad del 99.99% y una especificidad del 99.99%. Es decir, la probabilidad de que el test de positivo, dado que tenemos el virus (\(P(T^+|IKV)\)) es de 0.9999, y lo mismo ocurre para la probabilidad de que el test de negativo en caso de que NO tengamos el virus (\(P(T^-|\neg IKV)\)). Sabemos también que la incidencia del virus IKV es de 1 en 10000.
Herzog, Michael H, Gregory Francis, y Aaron Clarke. 2019. Understanding statistics and experimental design: how to not lie with statistics. Springer Nature.
Supongamos que somos elegidos aleatoriamente para realizarnos el test y este da positiv: ¿qué probabilidad hay de ser portadores del virus (\(P(IKV|T^+)\))? La primera respuesta que se nos viene es 0.9999 ¿verdad?. Pero, si estuvimos prestando atención, ya a esta altura debemos saber que para invertir la condicionalidad de una probabilidad tenemos que acudir al bueno de Bayes (de la sensibilidad \(P(T^+|IKV)\) a la que nos interesa \(P(IKV|T^+)\)). O sea:
donde \(P(T^+|IKV) = 0.9999\) y \(P(IKV) = 1/10000 = 0.0001\). Además, echando mano a la definición de probabilidad total podemos calcular \(P(T+)\) como:
¿Qué? ¿Esto significa que si el test me da positivo sólo tengo un 0.5 de probabilidad de tener el virus? ¿Esto quiere decir que los tests no sirven para nada? Momento, analicemos un poco el resultado al que llegamos. Lo que nos dice esta cuenta es que, una vez que el test nos da positivo, a pesar de lo sensible del test y por lo “raro” de la portación del virus, nuestra probabilidad de ser portadores es de 0.5. Pero, ¿y nuestra probabilidad de ser portadores si el test nos da negativos? Hagamos la cuenta:
OK, ahora la cosa tiene más sentido. O sea, el test es bastante bueno para decirnos cuando no somos portadores y dando negativo, el problema es cuando da positivo. En este caso tenemos que preocuparnos, pero, como vimos anteriormente, la probabilidad de ser portadores es de apenas 0.5.
Hay una solución más simple para esto y es la que deben estar pensando ustedes: ¿Y si me hacen un segundo test? ¡BINGO 🎊! Calculemos rápidamente la probabilidad de estar infectados si nos testean por segunda vez:
\[
P(IKV|T^{2+}) = \frac{0.9999^2 \times 0.0001}{0.9999^2 \times 0.0001 + 0.0001^2 \times 0.9999} = 0.9999
\tag{2.14}\] Ahora sí, si somos testeados por segunda vez, la probabilidad de ser portadores dado que tenemos dos resultados positivos trepa a 0.9999. Nos podemos quedar tranquilos.
Para cerrar, me gustaría que pensemos un poco en una palabra MUY importante que se dijo en el enunciado del problema: aleatoriamente. En muchos de los casos en los que nos testeamos para ver si somos portadores de un virus, lo hacemos porque tenemos algún tipo de presunción de que podemos serlo (por ejemplo, tenemos síntomas). ¿Cuál creen que sería la probabilidad que se modifica en la fórmula? Exacto, \(P(IKV)\), ya que sería más bien \(P(IKV|síntomas)\).
Ahora metamos un volantazo y hablemos un poco de las variables aleatorias y cómo medirlas y caracterizarlas.
2.7 Esperanza
La esperanza de una variable aleatoria \(X\), a veces también denominada media poblacional, es simplemente la suma pesada de todos sus valores posibles. No debemos confundir la esperanza con el promedio muestral, aunque, como veremos en breve, para algunos casos este último es un estimador insesgado de la esperanza.
La esperanza de una variable aleatoria discreta se define como:
\[
E(X) = \sum_{1}^\infty x_i p(x_i)
\tag{2.15}\]
En este caso es muy claro la naturaleza de promedio pesado, ya que a cada valor posible de \(X\) lo estamos pesando por su probabilidad. Sin embargo, para una variable aleatoria continua, en la que no tenemos definida una probabilidad puntual \(p(x_i)\) sino una función de densidad \(f(x)\)7, la definición es la siguiente:
7 La función de densidad \(f(x)\) es una función que describe la distribución de probabilidad de una variable aleatoria continua. La probabilidad de que la variable tome un valor dentro de un intervalo se calcula integrando la función de densidad sobre ese intervalo.
\[
E(X) = \int_{-\infty}^\infty x f(x) dx
\tag{2.16}\]
Como resulta esperable, la suma se transforma en una integral y la probabilidad puntual se reemplaza por \(f(x)\).
Algunas propiedades importantes de la esperanza son:
Por último, y a modo de aviso, advertencia y amenaza, recordemos que \(E(X)^2 \neq E(X^2)\).
2.8 Varianza y covarianza
La varianza nos da una idea acerca de la variabilidad de los procesos aleatorios que generan una variable aleatorio8. La varianza de la variable aleatoria \(X\) se define como:
8 Dato que será de vital importancia para sentar las bases de la inferencia estadística.
Por otro lado, la covarianza mide la cantidad de dependencia lineal entre dos variables aleatorias. Esta se define como
\[
Cov(X,Y) = E(XY) - E(X)E(Y)
\tag{2.20}\]
Si \(Cov(X,Y)>0\), esto indica que las dos variables se mueven en la misma dirección, mientras que si \(Cov(X,Y)<0\) esto indica que ambas variables se mueven en direcciones opuestas.
2.9 Correlación
Ahora una pregunta: ¿podemos comparar la covarianza de dos pares de variables? Por ejemplo, si \(Cov(X, Y) = 14.988\) y \(Cov(W, Z) = 0.001\), ¿podemos decir que X e Y están más relacionadas que W y Z? La respuesta es no, ya que la covarianza depende de la varianza de cada una de las variables, es decir, de la escala en la que se midan. Esto hace que la covarianza no sea una medida muy informativa para comparar la relación entre dos pares de variables. Para poder hacer esta comparación vamos a tomar el camino de la parsimonia y vamos a hacer lo que cualquier ser humano con Estadística II aprobada haría: normalizar la covarianza dividiéndola por las varianzas de cada una de las variables. Esto se llama correlación y nos dice cuánto covarían dos variables independizándose de la varianza de cada una de ellas. Esto la convierte en una medida muy relevante e informativa.
Si tenemos dos variables aleatorias X e Y, la correlación se define como la covarianza de sus versiones estandarizadas:
Y como \(a\) y \(b\) son constantes (en nuestro caso esperanzas), el único término que sobrevive es \(Cov(X,Y)\). Esta magnitud también es conocida como el coeficiente de correlación \(\rho\).
Con esta definición en la mano, si yo les digo que dos variables \(X\) e \(Y\) tienen una covarianza de \(14.988\) no les dice mucho, ¿No? Ahora, si les digo que el coeficiente de correlación es de \(0.788\) probablemente entiendan rápidamente que ambas variables están muy relacionadas9.
9 Si quieren divertirse, y de paso convertirse en ases de la determinación del coeficiente de correlación a ojímetro, les recomiendo este juegazo. Una estudiante ostenta el abultado récord de \(231\) puntos ¿La pasaste?
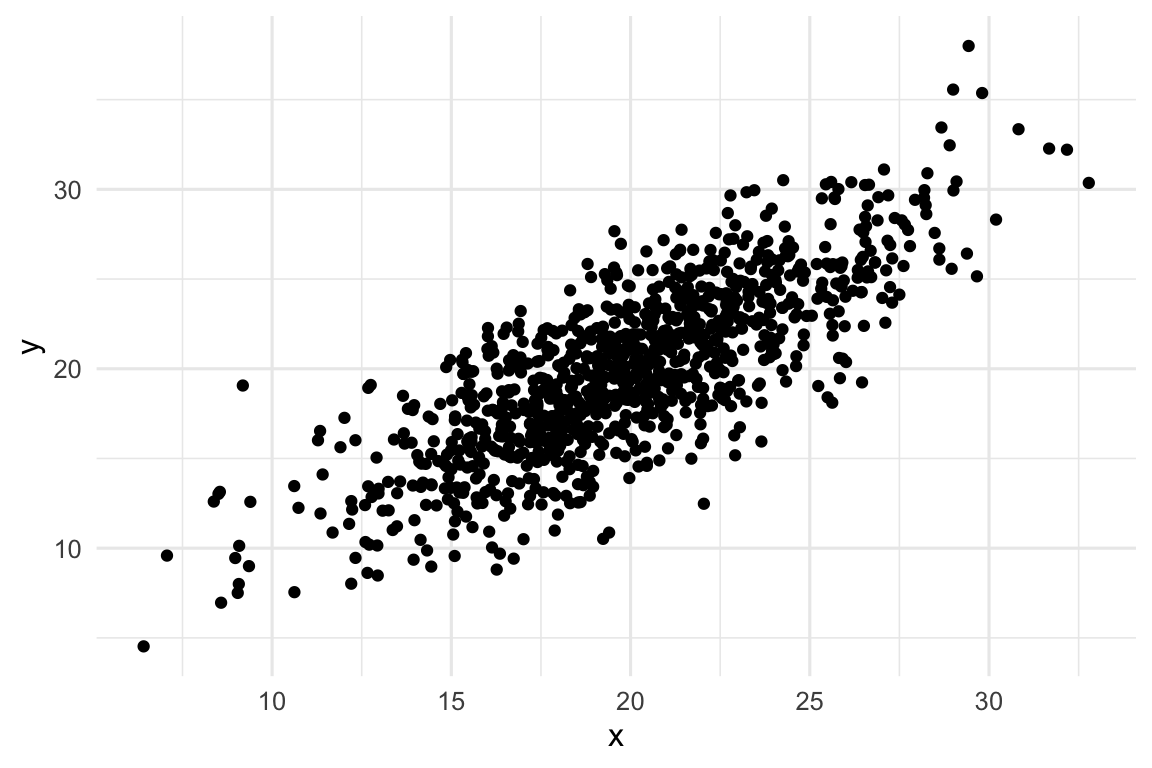
Veamos este ejemplo con números y de paso repasemos cómo se calcula la correlación en R:
Ver el código
set.seed(1234)x =rnorm(1000, 20, 4)y = x*.9+rnorm(1000, 2, 3)cat(paste("La covarianza entre X e Y es", round(cov(x,y), 3)))#> La covarianza entre X e Y es 14.988cat(paste("La correlación entre X e Y es", round(cor(x,y), 3)))#> La correlación entre X e Y es 0.788
Relación lineal entre X e Y.
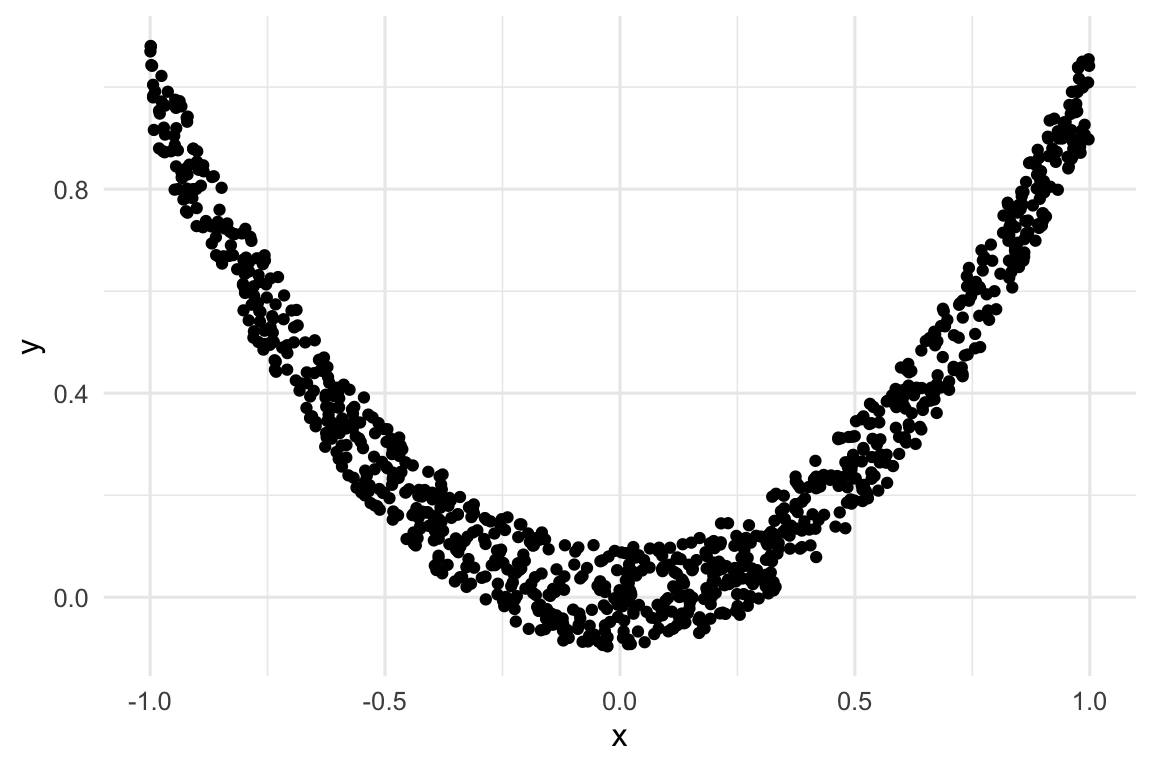
Es muy importante tener en cuenta que el coeficiente de correlación nos dice cuán linealmente relacionadas están las variables. Veamos esto con un ejemplito:
Ver el código
set.seed(1234)x =runif(1000, -1, 1)y = x^2+ .1*runif(1000, -1, 1)cat(paste("La covarianza entre X e Y es", round(cov(x,y), 3)))#> La covarianza entre X e Y es 0.01cat(paste("La correlación entre X e Y es", round(cor(x,y), 3)))#> La correlación entre X e Y es 0.055
Relación no lineal entre X e Y.
En este caso vemos que claramente hay una relación entre X e Y (no son una nube de puntos sin estructura), pero como esta relación no es lineal (cuadrática en nuestro caso), el coeficiente de correlación es cercano a cero.
Finalmente, tengamos en cuenta que el coeficiente de correlación puede tomar valores entre \(-1\) y \(1\). Una correlación positiva indica que las variables varían de la misma manera (si aumenta una aumenta la otra) y lo contrario ocurre con una correlación negativa (si aumenta una disminuye la otra). Cuanto más cerca esté el coeficiente de \(1\) o, más fuerte es la relación lineal.
2.10 Población y muestra
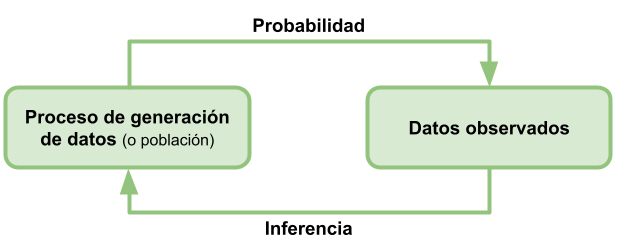
Veamos la siguiente figura. En ella podemos ver cómo hay una “población”10 de la que queremos saber algo. La teoría de probabilidad nos ayuda a “modelar” esta población(es decir, a definir una función de densidad que nos permita describir la generación de los datos). La inferencia estadística, por otro lado, nos ayuda a estimar los parámetros de esta función de densidad a partir de una muestra de datos. Por supuesto, en estas estimaciones hay aleatoriedad y si tomamos distintas muestras los resultados van a ser diferentes. Es aquí (o acá) donde entra la inferencia estadística, para ayudarnos a medir (o estimar) esta variabilidad y así poder cuantificar la confianza que tenemos en las conclusiones sobre la población a partir de la muestra.
10 Si bien podemos pensar en la población como el conjunto completo de individuos (u objetos o eventos) sobre los cuales se desea obtener información, creo que pensar en el proceso de generación de datos es una forma un poco más completa. Hagamos un pequeño ejercicio mental: si yo les preguntara cuál es el talle de zapatillas promedio de un estudiante de la Universidad de San Andrés. ¿Ustedes creen que la respuesta “poblacional” es medir el pie de todos los estudiantes que están este año en la universidad y calcular el promedio? Probablemente no, ya que esto es algo imposible de hacer. Lo que realmente queremos es conocer el proceso de generación de datos, es decir, la función de densidad que nos permita describir cómo se generan los datos (en este caso, la altura del pie de los estudiantes). Esto es lo que nos va a permitir hacer inferencias sobre la población a partir de una muestra.
Probabilidad e inferencia.
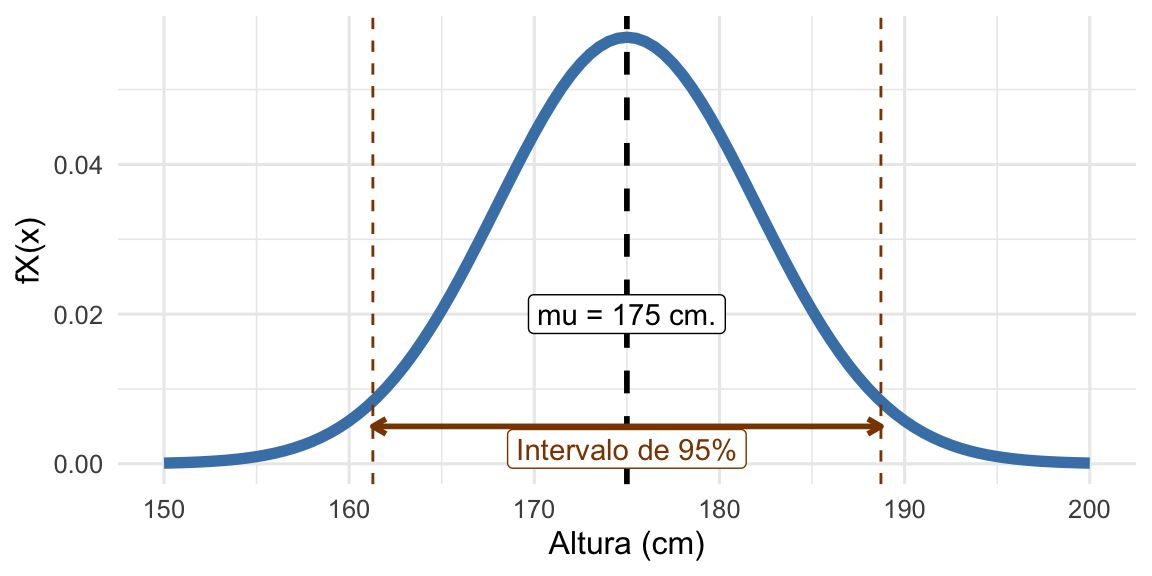
Vamos con un ejemplo que nos puede ayudar a entender de qué hablamos cuando hablamos de estimación. Supongamos que conocemos la distribución de la altura de la población de varones en Argentina (o sea, conocemos el proceso de generación de datos11). No estamos hablando de calcular el promedio de la altura de los varones, sino de que conocemos la función de densidad enla cual la altura de cada varón es una muestra. Si no queda del todo claro respiren hondo y esperen un poco que ya se va a ir aclarando. Entonces, la altura de los varones de Argentina tiene una distribución normal12 con media en cm. de \(\mu_{varones} = 175\) y una desviación estándar \(\sigma_{varones} = 7\), o, como ya aprendimos a decir: \(H_{varones} \sim \mathcal{N}(\mu_{varones},\sigma^2_{varones}) = \mathcal{N}(175, 49)\)13. A continuación podemos ver la función de densidad:
11 Está de más decir que nunca vamos a conocer esto, o que si lo conociéramos no estaríamos pensando en hacer inferencia ni estimar nada.
12 Como dijimos anteriormente, este no es un libro de probabilidad, así que si no saben lo que es la distribución normal pueden ir a leerlo a sus apuntes de estadística (procede a preguntarle a ChatGPT “¿Qué es la distribución normal?”).
13h del inglés height.
Función de densidad de probabilidad de la variabla aleatoria H (altura de los varones)
Ahora bien, en la figura podemos ver la función \(f_X(x)\) junto con una línea vertical que nos indica la media y dos líneas que nos indican los percentiles \(2.5\) y \(97.5\), es decir, que contienen el 95% de la masa de probabilidad. Todo esto es muy lindo pero estamos jugando a ser dios (o el Doctor Manhattan, o en lo que ustedes crean). Es imposible conocer los parámetros de esta distribución, pero lo que sí podemos hacer en la práctica es estimarlos. Estimar los parámetros de un modelo es el pan y la manteca de la inferencia estadística y el data mining. Como podemos ver en esta hermosa figura de Wasserman(Wasserman 2004), la teoría de probabilidad nos ayuda a definir modelos para la generación de datos y la inferencia estadística nos ayuda a estimar los parámetros esos parámetros.
Hay diversas formas de encontrar estimadores para los parámetros de un modelo (por ejemplo, método de los momentos, máxima verosimilitud, etc.) pero entenemos que eso excede los contenidos de este curso. Sin embargo, para estimar todos conocemos los estimadores de los parámetros poblacionales \(\mu\) y \(\sigma^2\). Claro, el promedio \(\bar{x}\) y el desvío muestral \(\hat{S}^2\):
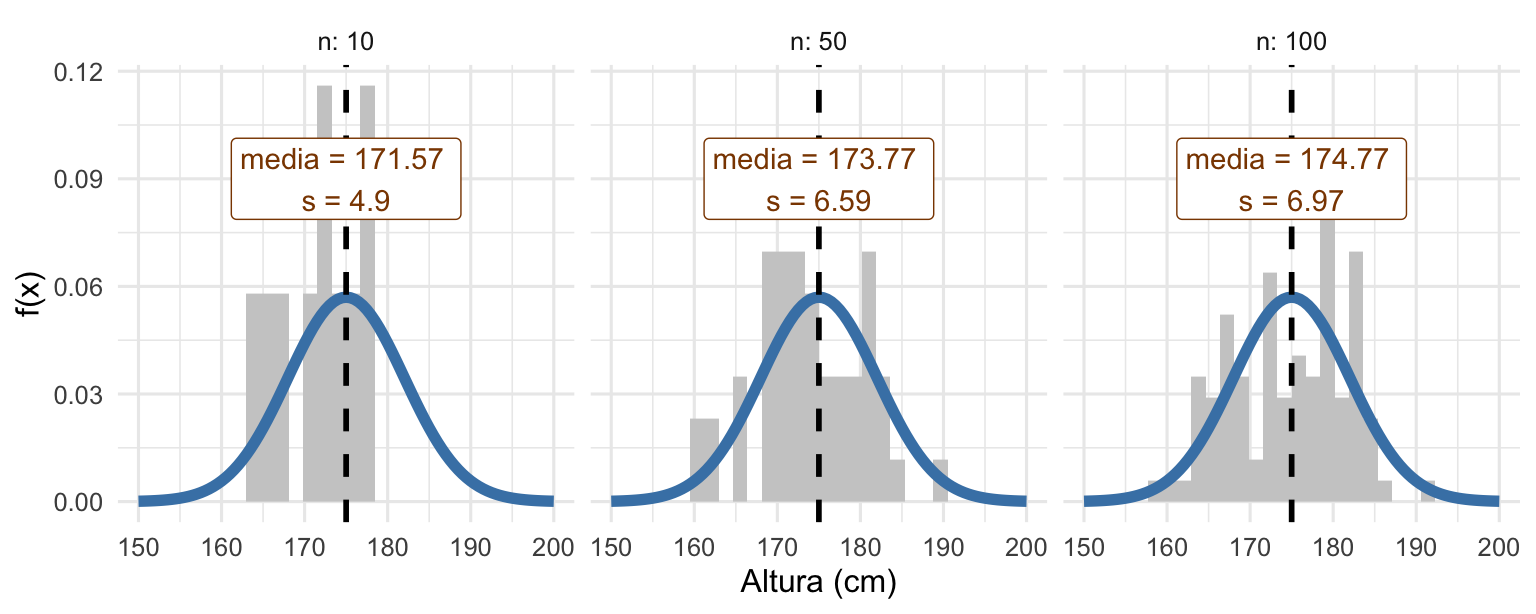
Simulemos tres experimentos tomando 10, 50 y 100 mediciones (\(n\)) y veamos los histogramas de estas muestras y sus estimaciones de \(\mu\) y \(\sigma\):
Distribución de la altura de los varones argentinos para distintos valores de n
Como es de esperarse, podemos ver que al aumentar \(n\), la estimación de los parámetros poblacionales es mejor. Pero tenemos que tener esta idea en mente, cada vez que tomamos una muestra podemos estimar un parámetro de la población y hasta hacer inferencias estadísticas sobre este mismo, pero nunca lo vamos a conocer.
Algo importante cuando usemos un estimador es que este sea consistente, lo que implica que si aumentamos \(n\) al infinito, el estimador converge al valor del parámetro (en este caso, el promedio muestral para \(n \to \infty\) tiende a la media poblacional \(\mu\)). Decimos, entonces, que un estimador converge en probabilidad a un determinado parámetro. Como usuarios de la estadística esto nos va a venir masticado y no nos vamos a tener que preocupar tanto, pero es bueno tenerlo en mente cuando hablamos de estimadores y estimaciones.
2.11 Inferencia estadística
Vamos a hacer un breve paseo por los conceptos clave de la inferencia estadística de la mano de un ejemplo.
TipEl ejemplo de inferencia
Supongamos que tenemos una página web de noticias y queremos probar una nueva feature con la que queremos aumentar el tiempo de retención de los usuarios. Para esto le vamos a presentar a los usuarios la versión nueva de la página y vamos a medir el tiempo que se mantienen en la página en ms14.
14 Probablemente lo más correcto para responder esta pregunta sea un A/B test, pero ya hablaremos de eso más adelante.
15 Además, como vamos a ver más adelante, cuando el \(n\) es lo suficientemente grande, esta condición deja de importar tanto.
Primero definamos nuestra variable aleatoria \(X\): “la diferencia de tiempo en ms entre después y antes del cambio”. Nuestro objetivo, entonces, es poder afirmar con cierto grado de seguridad si \(E(X)\) es igual a cero o distinta (nos importa tanto si aumenta como si disminuye). Empecemos con lo más sencillo, supongamos que \(X \sim \mathcal{N}(\mu, \sigma^2)\). Esta suposición no es tan loca ya que mucho procesos naturales se distribuyen de forma normal15. Supongamos también por un momento (más adelante vamos a relajar esta condición) que, ya sea por un experimento previo o porque somos magos, conocemos la \(\sigma^2\) de \(X\).
Como dijimos en el recuedro, si bien nuestro objetivo es probar si \(\mu\) es diferente de \(0\), esto lo vamos a hacer a partir de un experimento. Una vez que hagamos el experimento y midamos vamos a tener al clásico estimador de \(\mu\): \(\hat{\mu}=\bar{X}\), es decir, el promedio muestral. Ahora supongamos que el promedio nos da \(0.5\): ¿es distinto de cero?. Es natural pensar que para afirmar eso tenemos que conocer algo de su variabilidad, ¿no? Por ejemplo, no es lo mismo \(0.5\) con 20 mediciones que con 2000, ¿no? Para responder estos interrogantes vamos a utilizar las herramientas de la inferencia estadística.
Lo que vamos a querer hacer es rechazar \(H_0\) con cierto grado de confianza. Para esto vamos a comparar nuestra medición \(\bar{x}_{obs}\) con la distribución de los \(\bar{X}\) bajo \(H_0\).
Recordemos que si \(X \sim \mathcal{N}(\mu, \sigma^2)\) entonces \(\bar{X}_n \sim \mathcal{N}(\mu, \sigma^2/n)\)1617, donde \(n\) es la cantidad de realizaciones con las que yo calculo mi \(\bar{X}\). Entonces, si mi \(\bar{x}_{obs}\) medida está lo suficientemente lejos de \(0\) podemos decir que que \(\mu\) es diferente de cero. Pero: ¿qué es suficientemente lejos?
16 Es una cuenta que aparece en cualquier manual de estadística (procede a preguntarle a ChatGPT).
17 La \(n\) en \(\bar{X}_n\) es simplemente para enfatizar que es el promedio de una secuencia de \(n\) realizaciones.
Bueno, para responder esa pregunta vamos a tener que primero definir los errores que podemos cometer. Podemos cometer el error de decir que \(\mu\) es diferente de cero cuando no lo es (Error tipo I, falso positivo o rechazo de \(H_0\) cuando esta es verdadera) o podemos cometer el error de decir que \(\mu\) no es diferente de cero cuando sí lo es (Error tipo II, falso negativo o no rechazo de \(H_0\) cuando esta es falsa). Nuestro razonamiento va a ser empezar acotando el error de tipo I.
Para esto vamos a calcular qué tan probable es observar un valor igual o más alejado del cero que \(\bar{x}_{obs}\) dado que \(H_0\) es verdadera. Es decir, \(P(|\bar{X}|>\bar{x}_{obs}|H_0)\). Esta magnitud es lo que se conoce como el viejo y querido p-valor o p-value (si te gusta hacerte el canchero). En nuestro caso lo podemos calcular explícitamente. Empecemos estandarizando \(\bar{X}\) de la siguiente forma:
\[
Z = \frac{\bar{X} - \mu}{\sqrt{\sigma^2/n}} \sim \mathcal{N}(0,1)
\tag{2.26}\]
Y ahora que tenemos esta probabilidad, ¿qué hacemos?. Bueno, lo que podemos hacer es decir: si los datos vienen de \(H_0\) podemos calcular que tan “raros” son, entonces pongamos una cota en esa probabilidad y de esa forma estaremos acotando el error de tipo I en el largo plazo18. Así es que surge el famoso \(\alpha\) que normalmente hacemos valer \(0.05\)19. ¿Qué significa eso? Bueno, significa que, si la hipótesis nula fuera verdaera diríamos euivocadamente que hay un efecto cuando no lo hay el \(5%\) de las veces. Este párrafo se podría extender al infinito, pero por ahora quedémonos con esta interpretación “práctica” del p-valor (si se quedan con las ganas pueden ir a leer esto).
18 El enfoque frecuentista de la estadística justamente se basa en controlar los errores dada una repetición infinita de mi experimento.
19 Para una discusión más profunda sobre el tema de la selección de \(\alpha\) en la psicología experimental les recomiendo este hermoso artículo de Maier y Lakens (Maier y Lakens 2022).
Maier, Maximilian, y Daniël Lakens. 2022. «Justify your alpha: A primer on two practical approaches». Advances in Methods and Practices in Psychological Science 5 (2): 25152459221080396.
Entonces el camino es el siguiente: tomamos las medidas, calculamos el promedio, calculamos el p-valor y si este es menor que \(\alpha\) podemos decir que \(H_0\) es falsa. Todo muy lindo, pero siempre tengamos en mente que no sabemos exactamente si para esa realización estamos comentiendo un error de tipo I o no, y esa es una de las limitaciones de la estadística frecuentista.
Simulemos un experimento para \(n=50\) en el que nosotros conocemos tanto \(\sigma^2\) como \(\mu\):
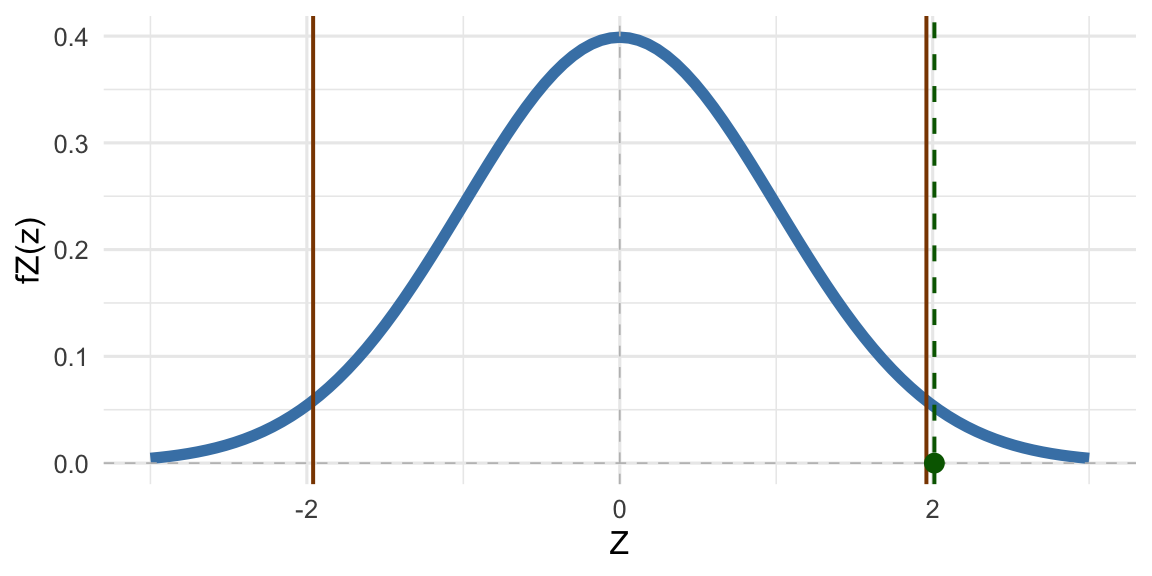
Acá vemos que, efectivamente, \(H_0\) es falsa ya que \(\mu=0.5\) (el verdadero parámetro poblacional). La media observada vale 0.569 y la media estandarizada (\(z_{\bar{x}}\)) vale 2.011. Miremos ccomo queda \(z_{\bar{x}}\) dentro de la distribución de los \(Z_{H_0}\) (los \(\bar{X}\) bajo \(H_0\) estandarizados):
#> Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
#> ℹ Please use `linewidth` instead.
Función de densidad de probabilidad de la variabla aleatoria H (altura de los varones)
La curva azul es la función de densidad de \(Z_{H_0}\), las líneas verticales naranjas delimitan los valores de \(Z\) en los cuales la probabilidad de encontrar valores más extremos es mayor a \(0.05\). En otras palabras, a la derecha de la línea naranja positiva y a la izquierda de la negativa vamos a estar en la región en la que consideramos a \(z_{\bar{x}}\) como evidencia significativa de que \(H_0\) es falsa. La suma de las integrales de la curva azul a la derecha de la línea naranja posiva y a la izquierda de la negativa da como resultado \(\alpha\).
El punto verde (y la línea punteada que lo acompaña) es nuestra observación \(z_{\bar{x}}\). O sea, todo parece indicar que, al controlar nuestro error de tipo I con \(\alpha=0.05\), el valor observado nos permite rechazar \(H_0\) o, como se dice habitualmente: “que \(\mu\) es significativamente diferente de cero”. Calculemos el p-valor y veamos si esto es efectivamente así.
cat(paste("El p-valor es:", round(2*pnorm(-mean(X)/sqrt(sigma^2/n)),3)))#> El p-valor es: 0.044
Que, como es menor que \(0.05\), nos permite rechazar \(H_0\).
Para resolver este ejemplo hicimos dos consideraciones que les pueden hacer ruido: 1. asumimos que conocíamos la desviación estándar de X; 2. asumimos que X tiene distribución normal.
2.11.1 ¿Qué pasa si no conozco \(\sigma\)?
Con respecto a 1, es natural que les haga ruido ya que en la mayoría de los casos no conocemos al \(\sigma\) poblacional, sino que lo vamos a estimar. Y, ¿cómo lo vamos a estimar? Echando mano del estimador insesgado de la desviación estándar \(S\). Este se define como:
cat(paste("la estimación de sigma es:", round(sd(X), 3)))#> la estimación de sigma es: 1.852
Bastante cercana al valor poblacional \(2\).
Ahora, no es cuestión de normalizar con este nuevo \(S^2\) y seguir como si nada. La cosa cambia y la distribución de \(\bar(X)\) estandarizado bajo \(H_0\) ya no tiene una distribución normal sino una distribución t de student con \(n-1\) grados de libertad. O sea:
Una buena noticia es que este p valor se puede calcular directamente con la función t.test(X) de la siguiente forma:
Ver el código
t.test(X)#> #> One Sample t-test#> #> data: X#> t = 2.1721, df = 49, p-value = 0.03472#> alternative hypothesis: true mean is not equal to 0#> 95 percent confidence interval:#> 0.04254842 1.09506577#> sample estimates:#> mean of x #> 0.5688071
Para cerrar, vale la pena mencionar que los parámetros \(\beta\) de un modelo lineal también tienen distribución t (los grados de libertad son más complejos). O sea que todo lo que vimos hasta acá de errores tipo I, tipo II, p-valor, etc. vale también para ellos.
2.11.2 ¿Qué pasa si X no se distribuye normalmente?
Ahora que ya vimos cómo pensamos cuando “hacemos” inferencia sobre la media, nos damos cuenta que más que interesarnos la distribución de los datos \(X\) nos interesa la de sus medias \(\bar(X)\) (si estiman algún parámetro de interés, claro). Y acá viene al rescate el teorema central del límite:
Este nos dice que distribución de la media estandarizada converge endistribución a una \(\mathcal{N}(0,1)\) sin importar la distribución de \(X\). Esto significa que si el \(n\) es lo suficientemente grande podemos estar tranquilos de que no es una asunción tan loca22.
22 Cuando las cosas no se pueden aproximar así hay solución, existen otros tests o simplemente tests que no asumen ninguna distribución (no paramétricos).
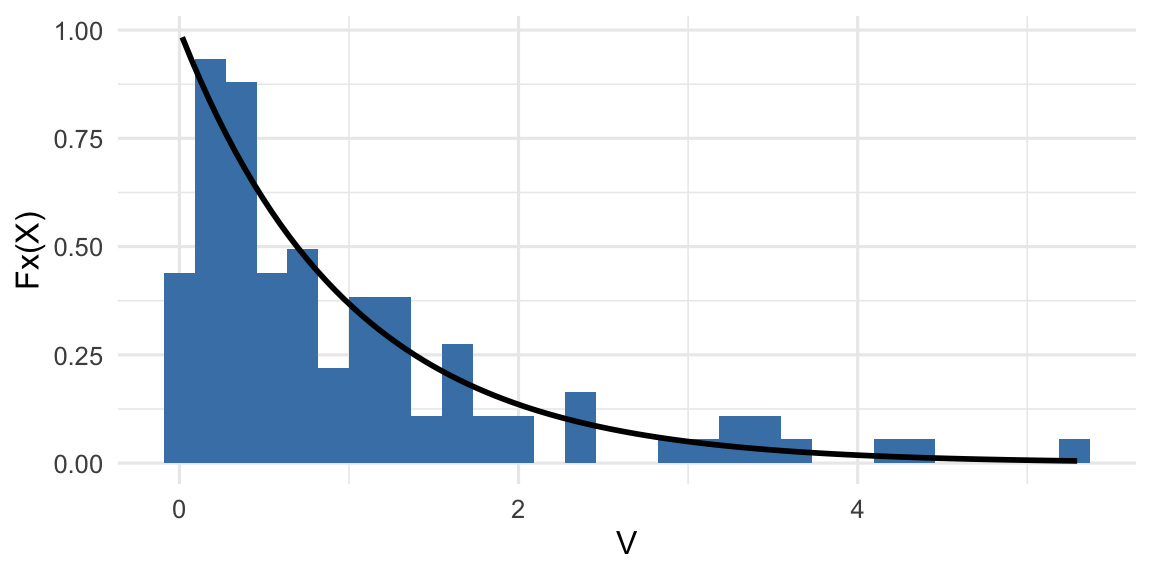
Supongamos que hay una variable aleatoria \(V \sim \mathcal{E}(\lambda=1)\) tal que \(E(V) = \lambda\). Si tomamos una muestra de \(n=100\) de \(V\), el histograma de esta se ve algo así:
Histograma de una muestra de 100 datos de una exponencial con lambda=1
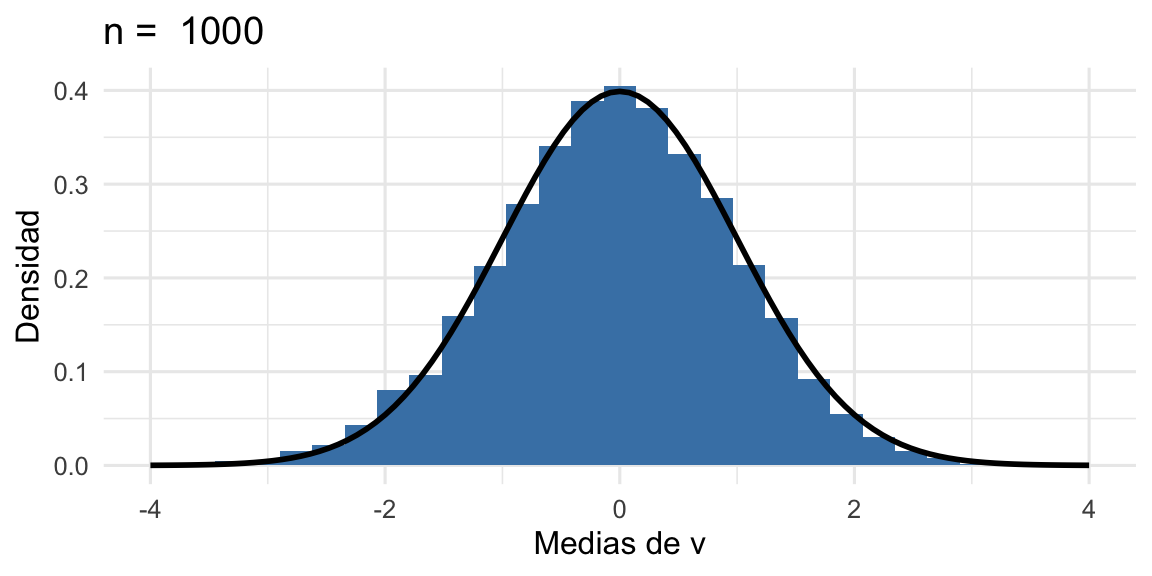
Donde en azul vemos el histograma y en negro la función de densidad para \(\mathcal{E}(\lambda=1)\). Ahora, qué pasa si tomamos \(1000\) muestras y hacemos el histograma de sus medias:
Ver el código
n =1000Zs <-c()set.seed(123)for (i in1:10000) { x <-rexp(n, rate =1) Zs <-c(Zs, (mean(x) -1)/sqrt(sd(x)^2/n))}Z_means <-tibble(Zs)Z_means %>%ggplot() +geom_histogram(aes(x = Zs, y = ..density..), fill ="steelblue") +stat_function(fun = dnorm, args =list(mean =0, sd =1), color ="black", linewidth =1) +labs(title =paste("n = ", n), x ="Medias de v", y ="Densidad") +scale_x_continuous(limits =c(-4, 4))#> Warning: Removed 2 rows containing non-finite outside the scale range#> (`stat_bin()`).#> Warning: Removed 2 rows containing missing values or values outside the scale range#> (`geom_bar()`).
Histograma de 1000 medias de muestras de 100 datos de una exponencial con lambda=1
Donde ahora la curva negra es una \(\mathcal{N}(0,1)\). Hagan la prueba con otras distribuciones u otros \(n\) y van a ver que rápido (o lento para las distribuciones altamente asimétricas) que convergen a una \(\mathcal{N}(0,1)\).
2.12 Potencia estadística
Ya hablamos de los errores de tipo I y prometimos hablar de los errores de tipo II. ¿Qué sería eso? Bueno, sería el caso en el que \(H_0\) fuera falsa y nosotros no la rechazáramos. A diferencia del contros de errores de tipo I, la probabilidad de cometer errores de tipo II (llamada muy originalmente \(\beta\)) depende del valor real de mi parámetro. En el ejemplo anterior, cuando \(H_0\) era verdadera \(\mu\) era igual a cero pero, ¿qué pasa cuando es falsa? ¿Qué valor de \(\mu\) tenemos que asumir?.
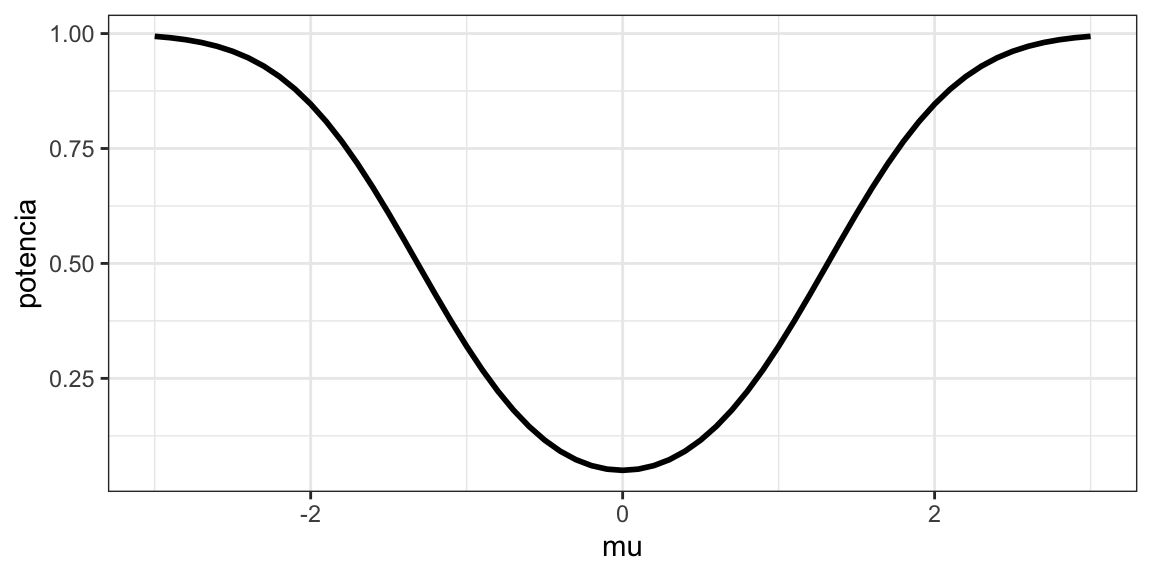
Empecemos definiendo a la potencia estadística, esta se define como \(1-\beta\), es decir, cuanto más acotado este el error de tipo II más alta será la potencia. Una definición formal podría ser:
Fijensé que para calcularla no sólo necesitamos a \(\sigma\) (que podríamos estimar) sino también a \(mu\), que es nuestro parámetro de interés. Por ejemplo, podemos ver que la pontencia depende de \(\mu\), en donde es más grande para valores de \(\mu\) más alejados del cero. Esto tiene sentido ya que a medida que \(|\mu|\) es mayor, es menor probable cometer errores tipo II.
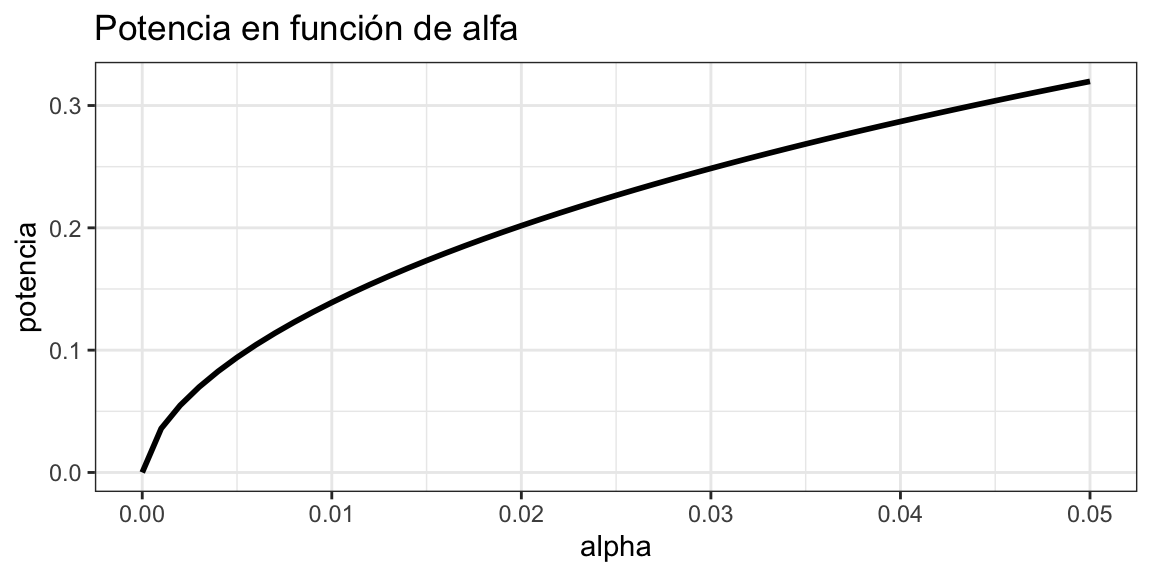
Como es de esperarse, la potencia también depende del \(\alpha\):
Como es de esperarse, la potencia también depende del \(\alpha\) ya que, cuanto menos estrictos nos ponemos para decir que hay un efecto, menos probabilidades de cometer un error de tipo II tenemos (pero más de tipo I pues la vida es una constante sucesión del problema de la manta corta).
Ver el código
pot <-potencia(3,1,20,seq(0, 0.05, 0.001))pot_tbl <-tibble(alpha =seq(0, 0.05, 0.001), potencia = pot)pot_tbl %>%ggplot(aes(x = alpha,y = potencia)) +geom_line(linewidth =1) +labs(title ="Potencia en función de alfa") +theme_bw()
Potencia estadística en función de alfa.
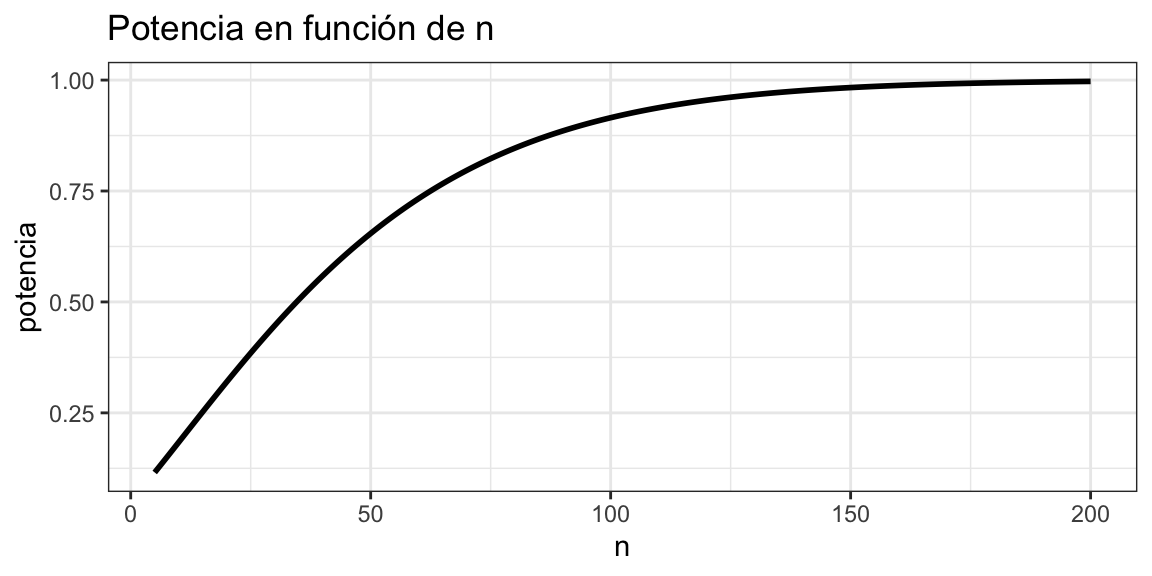
Finalmente, la potencia también depende del \(n\):
Ver el código
pot <-potencia(3,1,seq(5, 200),0.05)pot_tbl <-tibble(n =seq(5, 200), potencia = pot)pot_tbl %>%ggplot(aes(x = n,y = potencia)) +geom_line(linewidth =1) +labs(title ="Potencia en función de n") +theme_bw()
Potencia estadística en función de n.
Mientras el \(n\) sea más grande, los valores de potencia serán más altos. Es decir, si tengo una muestra más grande voy a cometer menos errores23. Esta última dependencia es muy importante.
23 Las distribuciones de \(H_0\) y \(H_1\) se hacen más finas y hay menos solapamiento, recuerden que en ambas la varianza disminuye con \(1/n\).
Hay una interpretación que nos gusta que es la siguiente: la potencia estadística es la lupa con la que miramos el problema. Es decir, si tenemos una potencia alta vamos a poder detectar diferencias pequeñas sin cometer demasiados errores. Supongamos que queremos diseñar un experimento con una potencia dada. El\(\alpha\) lo decidimos cuando acotamos el error de tipo I y a \(\mu\) no lo conocemos (algo vamos a hacer). Entonces, lo que más a mano nos queda para tener un experimento más potente es aumentar el \(n\).
El uso que se le da normalmente a esta herramienta es para determinar el mínimo tamaño de muestra necesario para un experimento24. El procedimiento es el siguiente:
24 Algo que se conoce normalmente como a-priori power analysis.
estimamos la variabilidad de nuestro experimento de alguna forma. Lo más usual es hacer un piloto, pero también puede ser un dato que salga de la bibliografía o de experimentos anteriores que hayamos realizado;
determinamos el mínimo tamaño de efecto de interés (SESOI25). Esta no es una determinación estadística sino que de dominio. Tenemos que conocer el problema y pensar en cuál sería el mínimo tamaño de efecto que consideraría relevante (relevante, no significativo). Esto a veces puede ser un poco confuso pero también nos obliga a pensar qué consideramos relevante en nuestro experimento;
una vez que tenemos estas dos magnitudes calculamos el tamaño de muestra para una potencia dada (por ejemplo \(0.9\)) y un \(\alpha\) dado (por ejemplo \(0.05\)).
25 Del inglés smallest effect size of interest.
No siempre resulta tan directo como en nuestro ejemplo, en el que podemos despejar explícitamente \(n\), pero la forma de pensar el problema es siempre similar.
Para más detalles sobre los procedimientos para justificar el temaño de muestra ver (Lakens 2022).
Con estos conceptos dejamos cerrado este breve -pero jugoso- repaso de probabilidad y estadística. Ya estamos listos para empezar a pensar en experimentos, relaciones causales y cuasiexperimentos. Nos vemos en el próximo capítulo.
2.14 Preguntas de repaso
¿Qué es una variable aleatoria? ¿Cuál es la diferencia entre una variable aleatoria discreta y una continua?
¿Qué es la esperanza de una variable aleatoria? ¿En qué se diferencia de la media muestral?
¿Por qué decimos que la media muestral es un estimador insesgado de la esperanza?
¿Qué mide la varianza de una variable aleatoria? ¿Y la covarianza entre dos variables? ¿Qué limitación tiene la covarianza como medida de asociación?
Tenemos dos pares de variables: X, Y y Q, P. Sabemos que \(cov(X,Y)= 0.8\), y \(cov(Q,P)= 0.059\). Si tuvieras que decir en cuál de los dos pares la relación es más fuerte, ¿qué dirías?
¿Qué es la probabilidad condicional? Escribí su fórmula y explicá con palabras qué significa \(P(A|B)\).
¿Qué es el p-valor?
Estás haciendo un test de hipótesis para evaluar la diferencia de medias en dos muestras. Tenés un valor observado que se aleja bastante de lo que esperarías si la hipótesis nula fuera cierta. ¿Qué quiere decir esto?
¿Qué es el error de tipo I y el error de tipo II? ¿Cómo se relacionan entre sí? ¿Qué rol juega α en su control?
Estás estudiando datos de accidentes de tránsito en CABA y te das cuenta que un 80% de las personas que presentaron lesiones graves tenían el cinturón de seguridad puesto. Tu amigo llega a la conclusión de que el cinturón de seguridad no sirve para prevenir lesiones graves. ¿Esto es correcto?¿Explicar por qué y cómo le explicarías?
¿Qué es la potencia estadística? ¿De qué factores depende?
Estás diseñando un experimento y querés saber a priori qué tamaño de muestra vas a necesitar, ¿que cosas necesitas definir o conocer?¿Por qué?
¿Por qué es importante el Teorema Central del Límite para la inferencia estadística, incluso cuando los datos no siguen una distribución normal?
¿Cuándo se usa la distribución t de Student en lugar de la distribución normal para construir un test? ¿Qué son los grados de libertad?
Querés estudiar el nivel de ansiedad en personas de entre 20 y 30 años en Argentina. ¿Cómo pensarías esa población?
2.15 Un caso aplicado para pensar
El Ministerio de Salud de la Provincia de Buenos Aires implementó un programa de vacunación contra el HPV en escuelas secundarias públicas. Para evaluar su impacto, un equipo de investigación recopiló datos de 500 alumnas de entre 13 y 15 años. Se midió, entre otras cosas, la cobertura vacunal (si recibió o no las dos dosis) y el nivel socioeconómico del hogar (NSE, medido en una escala continua de 0 a 100).
Los investigadores observaron lo siguiente:
El \(72%\) de las alumnas completó el esquema de vacunación.
La media de NSE de las alumnas vacunadas es \(54.3\) y la desviación estándar es \(12.1\).
La media de NSE de las alumnas no vacunadas es \(48.7\) y la desviación estándar es \(14.6\).
La covarianza entre NSE y cobertura vacunal es \(38.4\).
La covarianza entre NSE y asistencia escolar es \(310.2\).
Con estos datos, respondé las siguientes preguntas:
Un funcionario del ministerio afirma: “como el \(72%\) se vacunó, el programa fue un éxito y llegó a todos por igual.” ¿Qué problema tiene esta afirmación desde el punto de vista estadístico? ¿Qué información adicional necesitarías para evaluarla correctamente?
¿Podés comparar directamente la covarianza entre NSE y cobertura vacunal (\(38.4\)) con la covarianza entre NSE y asistencia escolar (\(310.2)\) para concluir cuál relación es más fuerte? ¿Por qué? ¿Qué harías en cambio?
El equipo quiere testear si la media de NSE de las vacunadas es significativamente distinta de la de las no vacunadas. Planteá las hipótesis nula y alternativa, explicá qué significa el p-valor en este contexto y qué error estarían cometiendo si rechazan H₀ cuando en realidad es verdadera.
Antes de arrancar el estudio, el equipo quiere determinar el tamaño de muestra necesario. ¿Qué información necesitan para calcularlo? ¿Por qué no alcanza con definir solamente el \(\alpha\)?
El equipo dice que quiere estudiar “la población de adolescentes argentinas”. ¿Cómo pensarías esa población en términos del proceso de generación de datos? ¿Es lo mismo que medir a todas las adolescentes del país?